Knowledge
From Data Catalog to Data Marketplace
Traditional data catalogs have long been the primary solution for managing data assets. However, their effectiveness is often limited by over-indexation and the lack of semantics and quality guarantees. Modern data architectures are built on data products with clear ownership, well-defined data contracts, and a focus on the needs of data consumers. These are brought together into an enterprise data marketplace to share managed data with other teams or organizations.
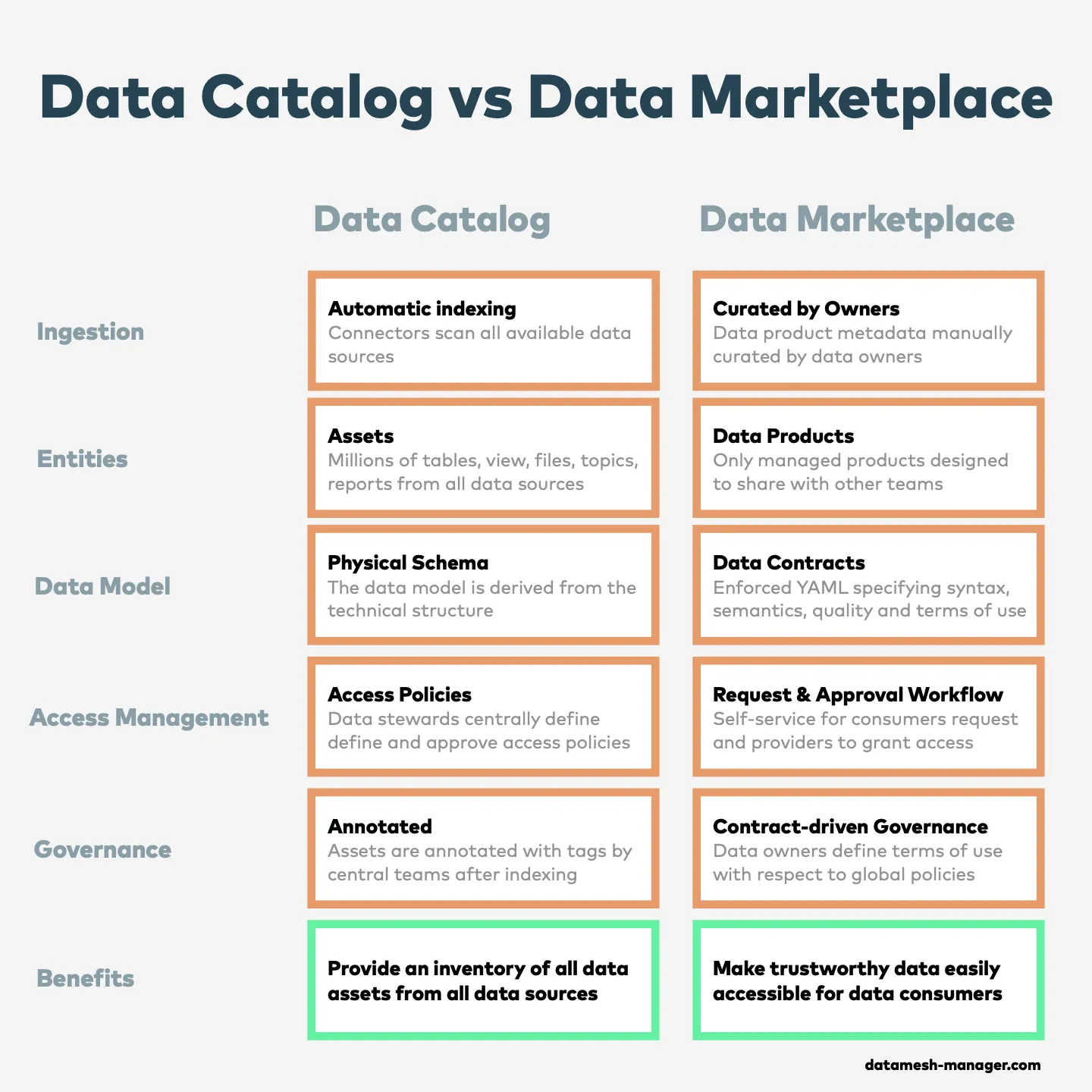
Data Catalogs: Indexing Data Assets
Data catalogs aim to provide a comprehensive inventory of an organization’s data assets to answer questions such as:
- What data is available?
- Where is the data located?
- What is the schema of the data?
- What are the statistical characteristics of the data?
- What is the lineage of the data?
- What is the usage of the data?
Historically, meta catalogs were required in data-lake-oriented architectures to specify the data structure in stored files and make them deserializable and accessible for structured queries (e.g., Hive Metastore, Project Nessie, Unity Catalog).
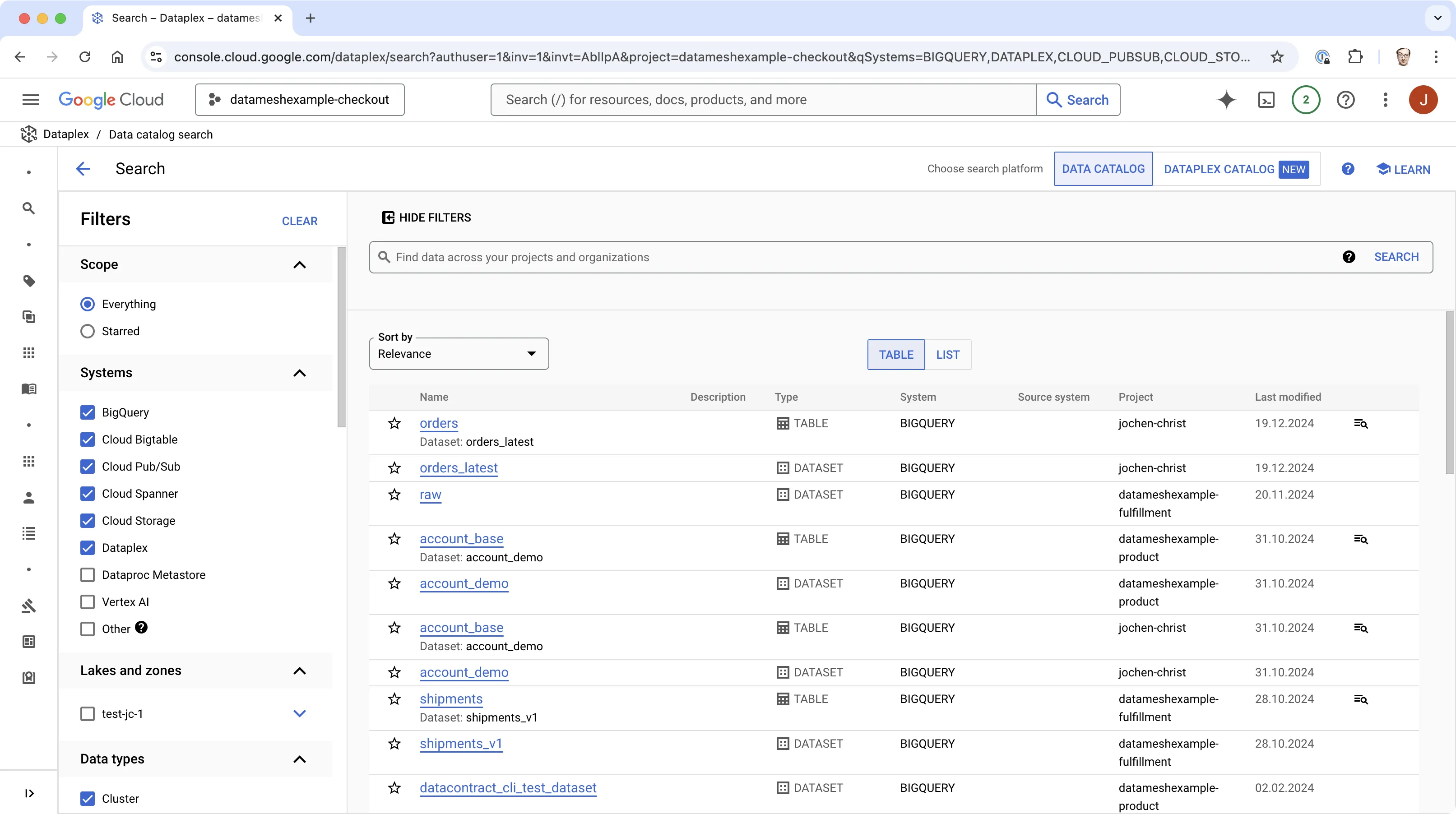
Over time, these solutions have been extended with discovery and governance features to data catalogs. Today, data catalogs are provided by all major data platforms (AWS Glue Catalog, Google Dataplex Catalog, Microsoft Azure Purview, Databricks Unity Catalog) as well as third-party vendors (e.g., Alation, Atlan, Collibra, Informatica, ...).
Why Data Catalogs Fail to Deliver Value in Organizations
In many organizations, data catalogs are underutilized despite significant investments in their development and maintenance. At first glance, the concept of a centralized repository for indexing all data assets seems indispensable in today’s data-driven world. However, in practical reality, we often observed a contrast to this ideal. The primary reason lies in — what we call — the over-indexation of assets and the lack of semantic, actionable information within these catalogs.
Over-Indexation: A Flood of Irrelevant Data
Data catalogs have connectors for all major data sources, such as databases, data lakes, data warehouses, BI tools, and data pipelines. When every data source is automatically fully indexed, the data catalogs includes domain data that is valuable to business — but also all the intermediate tables, raw tables, and outdated datasets are indexed that are irrelevant to most data consumers. Teams are left sifting through a sea of datasets, many of which are incomplete, outdated, or irrelevant to their specific needs - especially when the semantics and business context is not clear. Almost all of these automatically indexed assets are undocumented. This over-indexation creates an information overload, making it difficult for users to identify the actual valuable and trustworthy data assets.
Data catalogs quickly build indexes with millions of indexed tables, views, files, topics, dashboards, reports, and other data objects.
The Bystander Effect
The Bystander Effect is a social psychological phenomenon where individuals are less likely to offer help or take action in a situation when there are other people present. The presence of others diffuses the sense of responsibility, leading people to assume that someone else will step in or that their action is not necessary. In the context of a data catalog with millions of indexed but undocumented assets the Bystander Effect can manifest as a reluctance among users to take responsibility for documenting or improving the catalog. With millions of assets, each individual may assume that someone else—another team, department, or colleague—is better suited or more obligated to document or improve a particular metadata. The sheer scale of the problem makes users feel that their individual contributions would be insignificant or unnoticed, reducing their motivation to act. They might perceive documenting assets as a thankless or low-priority task.
Of course, data catalogs support adding documentation and tags to improve metadata, and data stewards encourage team to do so. But actually nobody wants to be the first and only one to start cleaning up the mess. It is frustrating to spend time on documenting and cleaning up data, while the vast majority of data assets remain undocumented and in low quality.
Too Many Technical Details - Disconnected from Business
Another major issue is the focus on technical metadata. While information about schema structures, field types, and lineage is helpful for engineers, it does little to address the needs of business users who rely on semantic clarity and quality assurance.
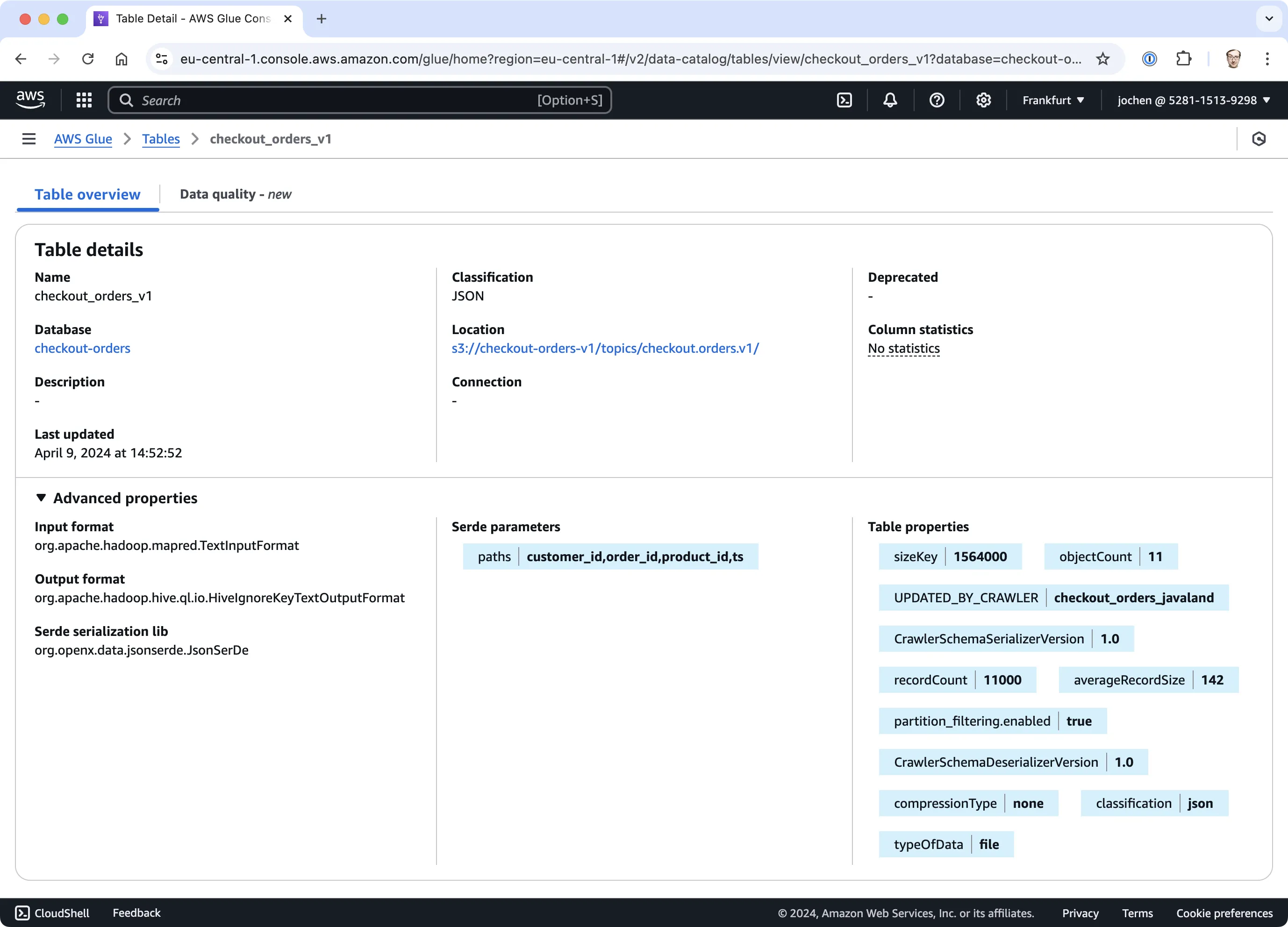
Most data catalogs fail to capture or communicate the following critical aspects:
- Semantics: Business users need to understand what data represents in a specific domain context, and under which business processes data has been generated. This requires clear definitions, relationships, and examples—not just technical schemas.
- Data Quality: Users need to know whether the data is complete, consistent, and fit for purpose. Yet, most catalogs fail to provide a clear assessment of these factors.
- Service-Level Expectations: A dataset’s reliability, availability, and update frequency are essential for determining its usability in operational and analytical processes. Without this information, trusting the data becomes a gamble.
This aspects cannot be automatically extracted from the data sources, but require manual curation and domain knowledge.
Towards a New Paradigm: Enterprise Data Marketplace
Data products are transforming the way organizations with distributed teams manage and share data. They represent a shift towards a consumer-focused approach to data management.
Data Products: Build for Consumers with Clear Ownership
Data products are logical units built around a business concept, combining assets, code, and documentation to deliver a coherent data solution for consumers. They hide implementation details (such as raw and intermediary tables, code pipelines, test data) to only show the final curated datasets to other teams over defined output ports. A data product is typically owned by the team that understands the business domain and the result of a deliberate decision to share the data as a product.
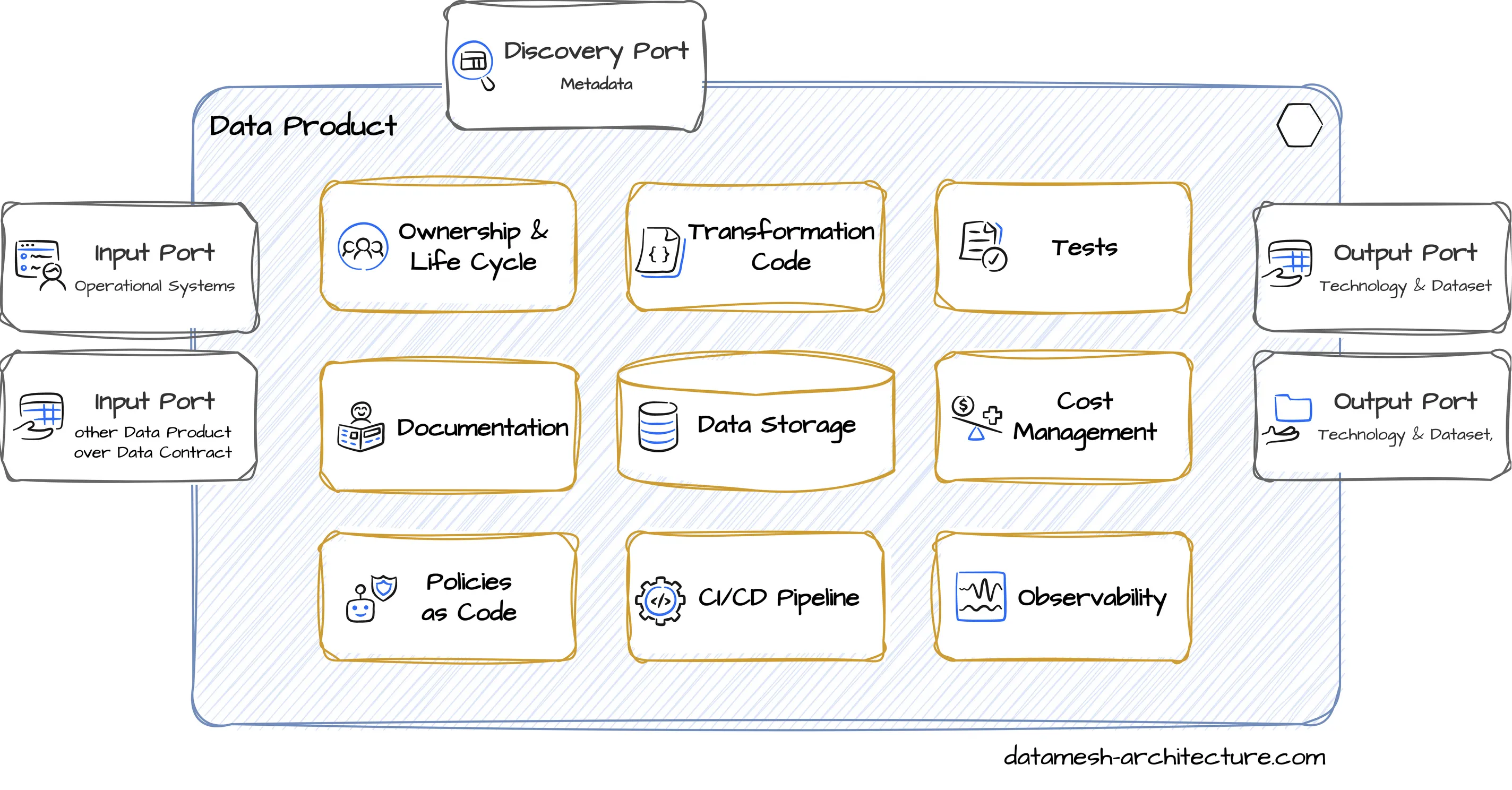
Most organizations only have 100s to 1000s of data products, which makes it much easier to manage and maintain, compared to the millions of indexed data assets in traditional data catalogs.
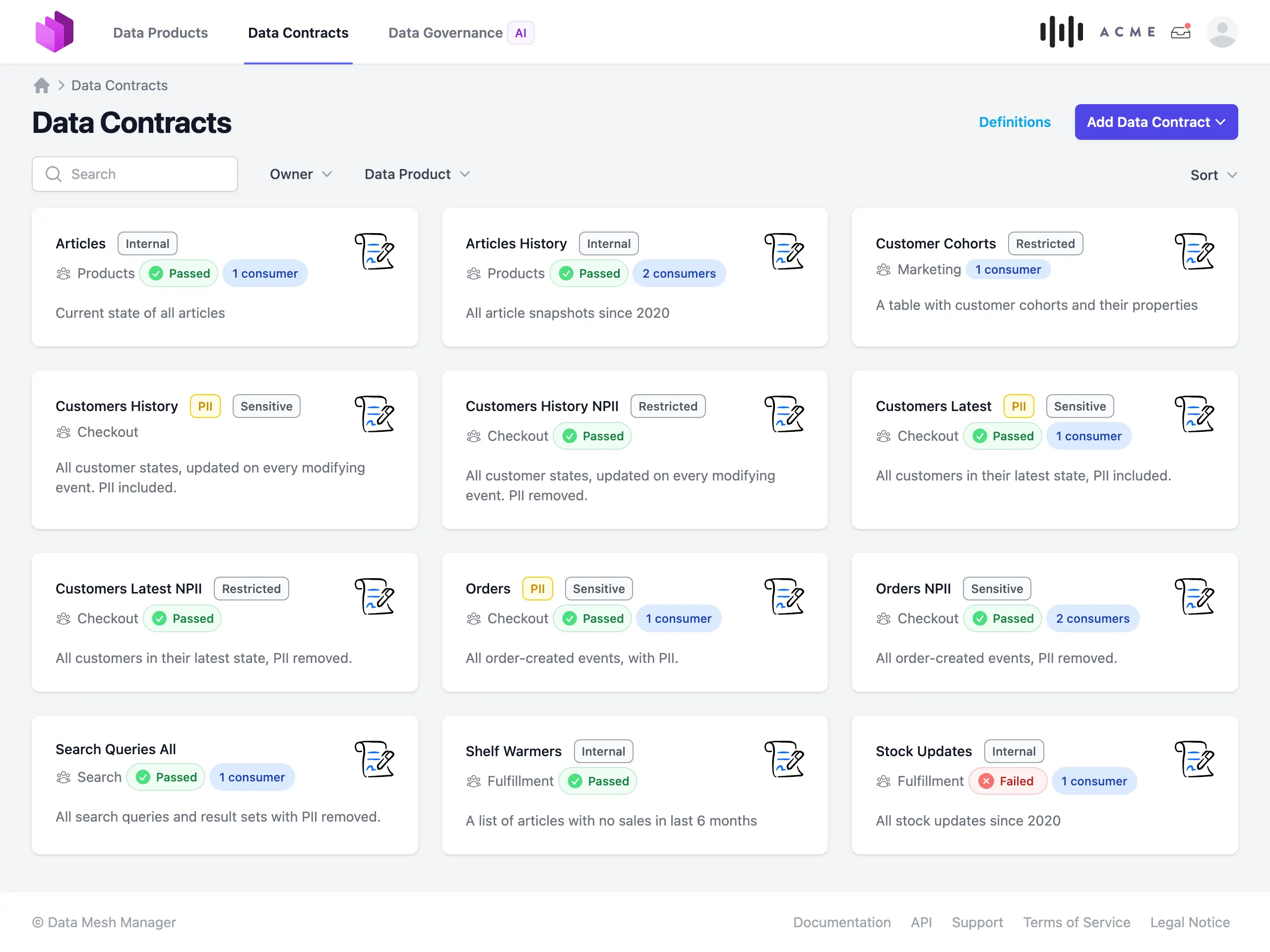
Data Contracts: Explain and Verify Syntax, Semantics, and Quality
When providing data products, we need to describe and explain the provided data to potential data consumers. This is where data contracts come into play. A data contract defines the structure, format, semantics, quality metrics, SLAs, and terms for data exchanges between providers and consumers. Technically, a data contracts is a standardized YAML specification that is both human-readable and machine-readable (see Data Contract Specification and ODCS). Data contracts are manually curated by product owners and consumers through a collaborative requirements engineering process. The data platform then tests, validates, and enforces compliance of data products with these contracts.
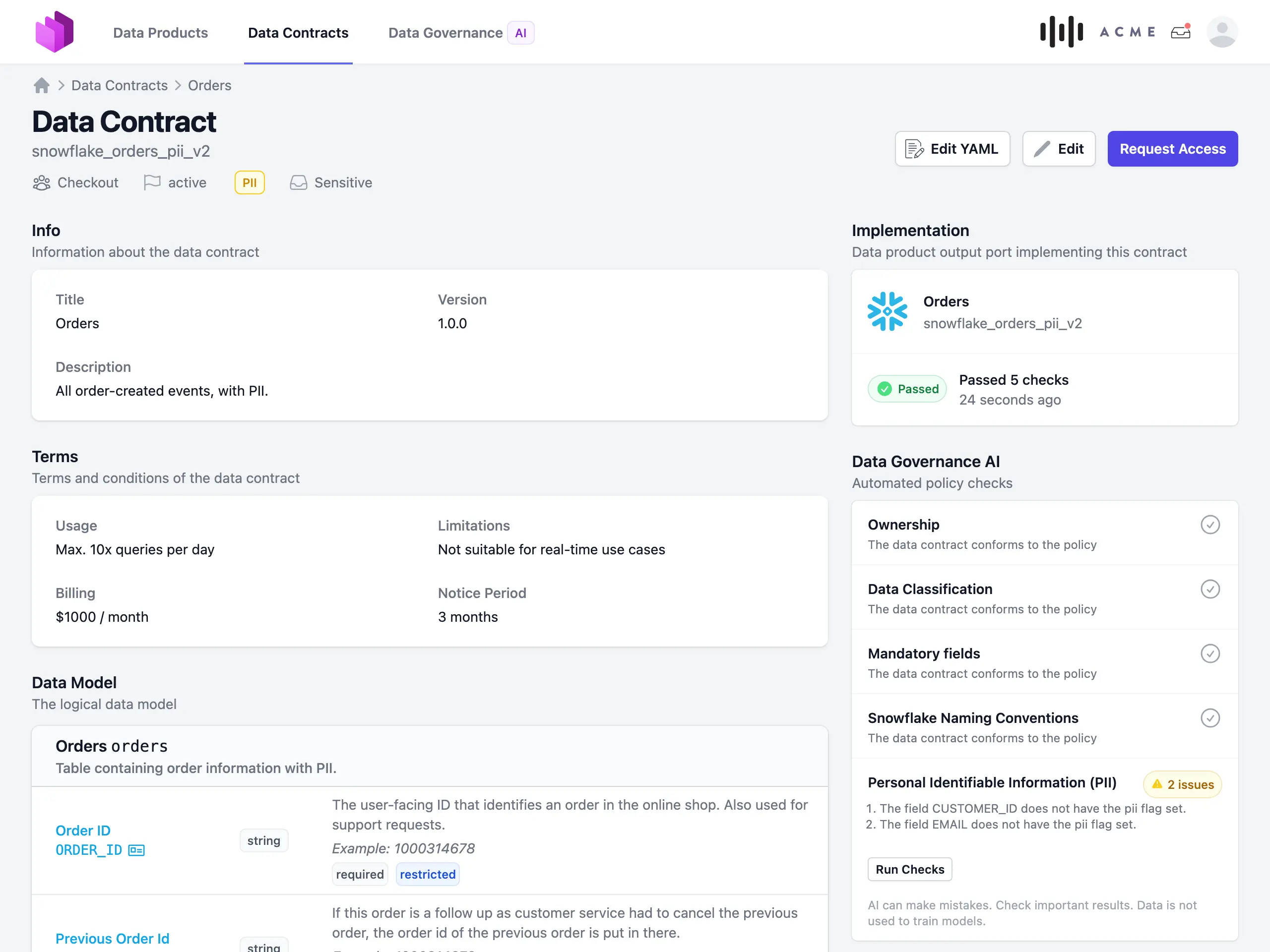
Data contracts are for data products what APIs have been for software systems. They provide a clear interface specification that allows data consumers to build on top of the data product without having to understand the underlying implementation details.
Self-service Request and Approval Workflow
When we bring data products with their data contracts together in an enterprise data marketplace, we can enable a self-service for access management.
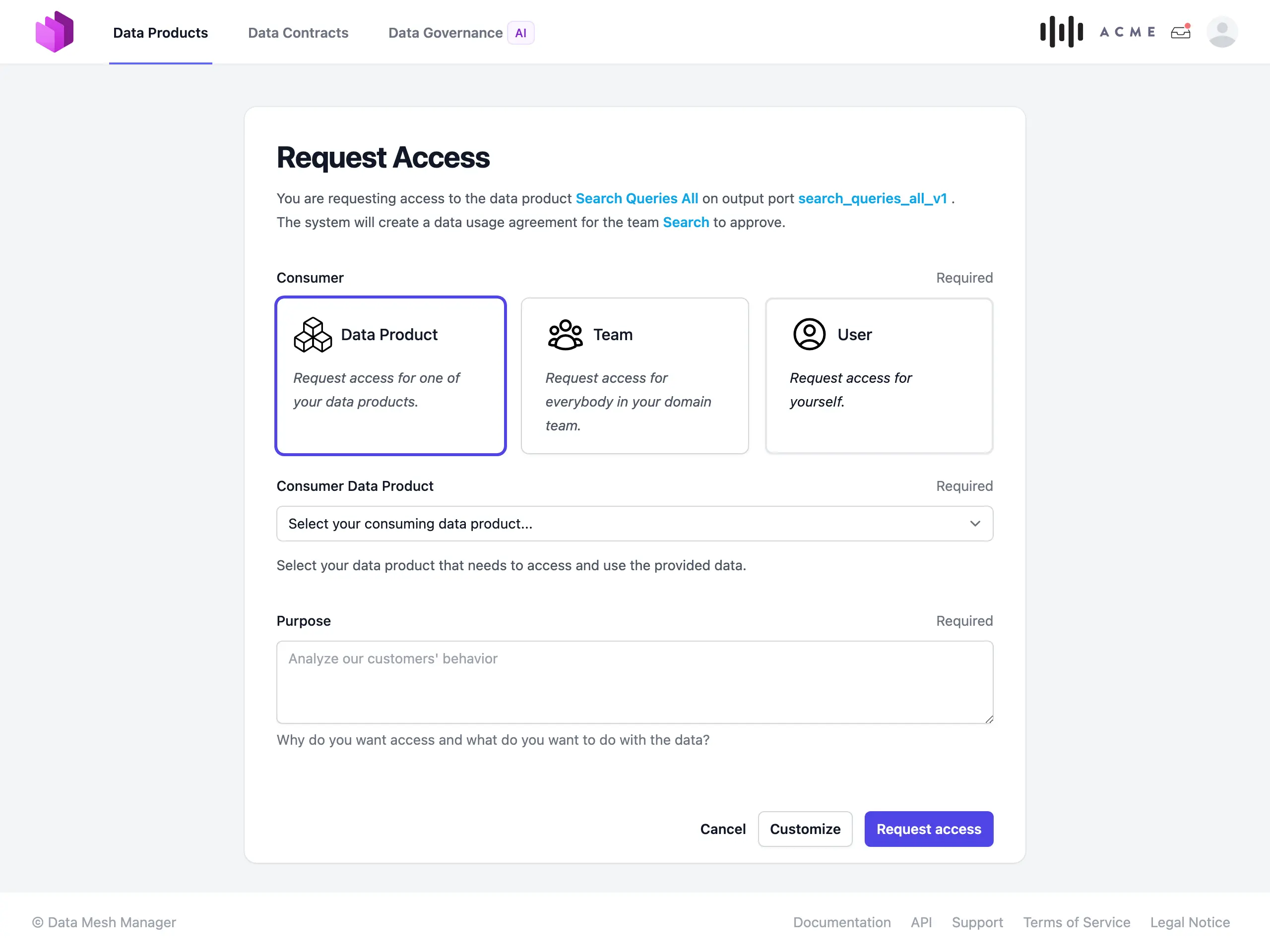
Data consumers can request access to data products in adherence to data contract terms. Data product owners are responsible for approving or rejecting access requests based on their domain expertise and governance rules. The data platform automates access rights management, ensuring efficient and secure handling of data product assets. This self-service workflow eliminates bottlenecks caused by centralized governance delays. A comprehensive audit trail of access requests, approvals, and active consumers ensures full transparency to data producers and governance teams.
Contract-Driven Data Governance
Effective governance in a data marketplace relies on clear ownership and stable data contracts. Global policies set the baseline rules that apply universally across all data products, ensuring consistency in the marketplace. Data contracts build on these policies by specifying domain-specific details such as terms of use, quality standards, and compliance requirements, making them essential for trustworthy exchanges between producers and consumers.
Data product owners are accountable for ensuring their offerings meet the agreed-upon standards and remain compliant with both global policies and contract-specific guarantees. By maintaining their data products and collaborating with consumers, owners ensure the marketplace operates efficiently and reliably.
We can leverage AI in data governance by monitoring metadata, validating compliance, and detecting potential risks. With good metadata, LLMs can create recommendations and warnings to data product owners to streamline their responsibilities. However, ultimate accountability lies with the owners, whose domain expertise ensures governance decisions are both practical and aligned with business objectives.
Summary
Data catalogs have long been the primary solution for managing data assets. However, their effectiveness is often limited by over-indexation and the lack of semantics and quality guarantees. Effective data product metadata are data-contract-driven, manually curated, and have clear ownership. In a data marketplace, organizations can share managed data products with other teams or external organizations in a self-service manner and with clear governance rules.
Entropy Data as Data Marketplace
Learn more about how Entropy Data can help you to build an enterprise data marketplace.
Start for Free, explore the clickable demo of Entropy Data, or Book a Guided Tour with the authors.